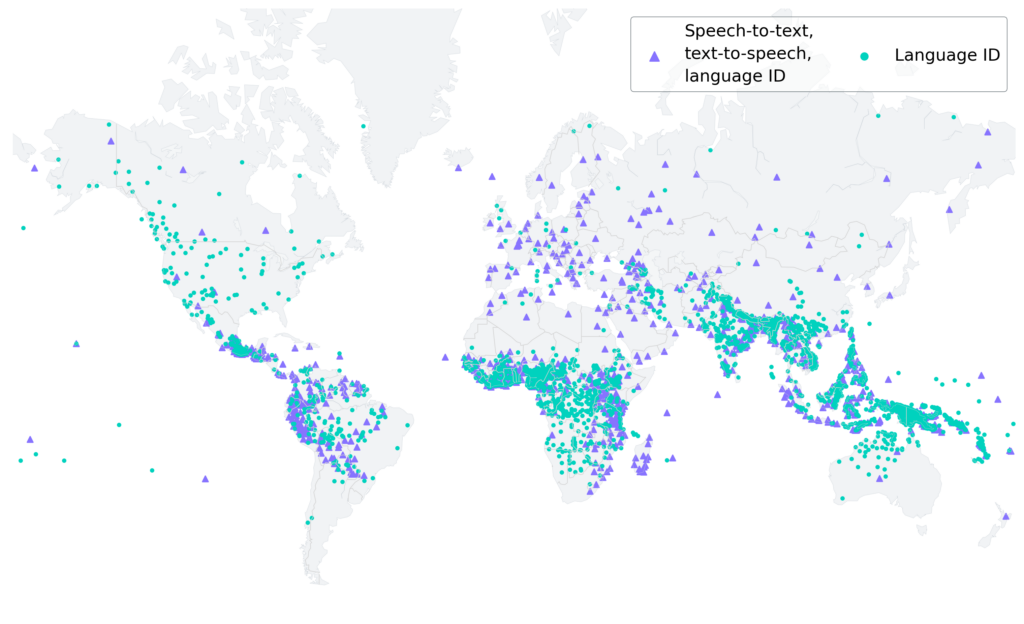
1100+语言的语音识别和语音合成技术新突破 by AIBackup 2023-05-24 written by AIBackup 2023-05-24 136 Facebook AI研究团队近日在其官方博客上发布了一项新的多语言语音识别和语音合成技术,该技术可以支持1100多种语言,这是一个前所未有的突破。这项技术基于大规模多语言语音(MMS)项目,利用公开可用的宗教文本进行自我监督学习,实现了语音到文本、文本到语音以及语言识别等功能。MMS项目的主要目标是扩大语音技术的语言覆盖范围,以便为更多人提供便利。目前,大多数语音技术只支持约100种语言,这只是全球7000多种语言的一小部分。MMS项目通过新的数据集和自我监督学习的有效利用,将支持的语言数量增加了10-40倍。 MMS项目的数据集基于公开可用的宗教文本的朗读。研究人员构建了预训练的wav2vec 2.0模型,覆盖了1406种语言,一个支持1107种语言的多语言自动语音识别模型,以及相同数量语言的语音合成模型,还有一个支持4017种语言的语言识别模型。实验表明,该多语言语音识别模型将FLEURS基准测试中54种语言的词错误率降低了一半以上,而且只需要少量的标注数据进行训练。此外,MMS项目还提供了一个新的数据集,包含了1107种语言的标注数据和3809种语言的未标注语音数据。这些数据的获取和处理都需要经过精心的策划和设计,以确保其能够用于构建高质量的模型。总的来说,MMS项目的推出,将极大地扩大语音技术的语言覆盖范围,为全球更多的语言使用者提供信息获取的便利。相关资料:Facebook AI官方博客MMS项目GitHub页面MMS项目相关论文1MMS项目相关论文2 You Might Also Like AI大清洗:生成型AI如何改变SEO内容流量、工作岗位和依赖网站的未来 数字化诗词:chinese-poetry数据库,古诗文的全新呈现 融合注意力评分解码的脉冲生成对抗网络 Zoo:AI图像模型的对比乐园 FacebookAIMMS项目人工智能多语言处理语音合成语音识别 分享 Twitter previous post 开源AI生态系统的一瞥:从神经网络到3D建模 next post Text2NeRF:用神经辐射场实现文本驱动的3D场景生成 也许你还会喜欢 OpenAI推出新功能:函数调用,AI计算能力再升级(案例) 2023-06-14 AI新突破:零样本文本引导的视频到视频转换技术 2023-06-14 Galactic:以每秒100k步速度扩展端到端强化学习的重排任务 2023-06-14 超越人类:探索“磨刀人”和生物黑客的未来 2023-06-11 数据工程领域30个最实用的Python库 2023-06-11 AI大清洗:生成型AI如何改变SEO内容流量、工作岗位和依赖网站的未来 2023-06-07